Handling Time#
When performing feature engineering with temporal data, carefully selecting the data that is used for any calculation is paramount. By annotating dataframes with a Woodwork time index column and providing a cutoff time during feature calculation, Featuretools will automatically filter out any data after the cutoff time before running any calculations.
Note
This guide focuses on performing feature engineering on temporal data, but it is not specific to feature engineering for time series problems, which are their own class of machine learning problems. A guide on using Featuretools for time series feature engineering can be found here.
What is the Time Index?#
The time index is the column in the data that specifies when the data in each row became known. For example, let’s examine a table of customer transactions:
[2]:
import featuretools as ft
es = ft.demo.load_mock_customer(return_entityset=True, random_seed=0)
es["transactions"].head()
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
[2]:
| transaction_id | session_id | transaction_time | product_id | amount | _ft_last_time | |
|---|---|---|---|---|---|---|
| 10 | 10 | 1 | 2014-01-01 00:00:00 | 5 | 127.64 | 2014-01-01 00:00:00 |
| 2 | 2 | 1 | 2014-01-01 00:01:05 | 2 | 109.48 | 2014-01-01 00:01:05 |
| 438 | 438 | 1 | 2014-01-01 00:02:10 | 3 | 95.06 | 2014-01-01 00:02:10 |
| 192 | 192 | 1 | 2014-01-01 00:03:15 | 4 | 78.92 | 2014-01-01 00:03:15 |
| 271 | 271 | 1 | 2014-01-01 00:04:20 | 3 | 31.54 | 2014-01-01 00:04:20 |
In this table, there is one row for every transaction and a transaction_time column that specifies when the transaction took place. This means that transaction_time is the time index because it indicates when the information in each row became known and available for feature calculations. For now, ignore the _ft_last_time column. That is a featuretools-generated column that will be discussed later on.
However, not every datetime column is a time index. Consider the customers dataframe:
[3]:
es["customers"]
[3]:
| customer_id | zip_code | join_date | birthday | _ft_last_time | |
|---|---|---|---|---|---|
| 5 | 5 | 60091 | 2010-07-17 05:27:50 | 1984-07-28 | 2014-01-01 08:09:40 |
| 4 | 4 | 60091 | 2011-04-08 20:08:14 | 2006-08-15 | 2014-01-01 05:31:30 |
| 1 | 1 | 60091 | 2011-04-17 10:48:33 | 1994-07-18 | 2014-01-01 07:26:20 |
| 3 | 3 | 13244 | 2011-08-13 15:42:34 | 2003-11-21 | 2014-01-01 09:00:35 |
| 2 | 2 | 13244 | 2012-04-15 23:31:04 | 1986-08-18 | 2014-01-01 08:23:45 |
Here, we have two time columns, join_date and birthday. While either column might be useful for making features, the join_date should be used as the time index because it indicates when that customer first became available in the dataset.
Important
The time index is defined as the first time that any information from a row can be used. If a cutoff time is specified when calculating features, rows that have a later value for the time index are automatically ignored.
What is the Cutoff Time?#
The cutoff_time specifies the last point in time that a row’s data can be used for a feature calculation. Any data after this point in time will be filtered out before calculating features.
For example, let’s consider a dataset of timestamped customer transactions, where we want to predict whether customers 1, 2 and 3 will spend $500 between 04:00 on January 1 and the end of the day. When building features for this prediction problem, we need to ensure that no data after 04:00 is used in our calculations.
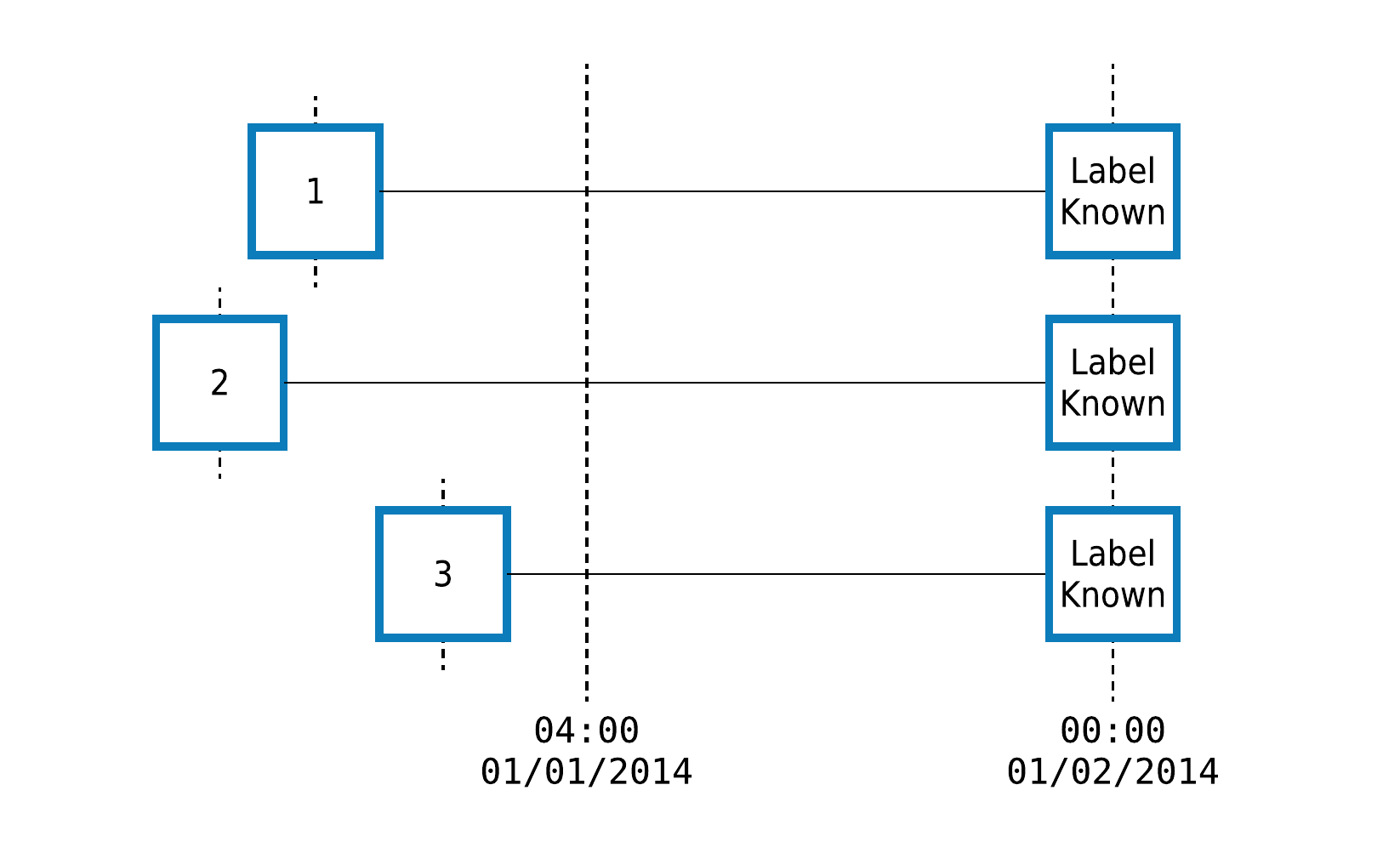
We pass the cutoff time to featuretools.dfs() or featuretools.calculate_feature_matrix() using the cutoff_time argument like this:
[4]:
fm, features = ft.dfs(
entityset=es,
target_dataframe_name="customers",
cutoff_time=pd.Timestamp("2014-1-1 04:00"),
instance_ids=[1, 2, 3],
cutoff_time_in_index=True,
)
fm
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
[4]:
| zip_code | COUNT(sessions) | MODE(sessions.device) | NUM_UNIQUE(sessions.device) | COUNT(transactions) | MAX(transactions.amount) | MEAN(transactions.amount) | MIN(transactions.amount) | MODE(transactions.product_id) | NUM_UNIQUE(transactions.product_id) | SKEW(transactions.amount) | STD(transactions.amount) | SUM(transactions.amount) | DAY(birthday) | DAY(join_date) | MONTH(birthday) | MONTH(join_date) | WEEKDAY(birthday) | WEEKDAY(join_date) | YEAR(birthday) | YEAR(join_date) | MAX(sessions.COUNT(transactions)) | MAX(sessions.MEAN(transactions.amount)) | MAX(sessions.MIN(transactions.amount)) | MAX(sessions.NUM_UNIQUE(transactions.product_id)) | MAX(sessions.SKEW(transactions.amount)) | MAX(sessions.STD(transactions.amount)) | MAX(sessions.SUM(transactions.amount)) | MEAN(sessions.COUNT(transactions)) | MEAN(sessions.MAX(transactions.amount)) | MEAN(sessions.MEAN(transactions.amount)) | MEAN(sessions.MIN(transactions.amount)) | MEAN(sessions.NUM_UNIQUE(transactions.product_id)) | MEAN(sessions.SKEW(transactions.amount)) | MEAN(sessions.STD(transactions.amount)) | MEAN(sessions.SUM(transactions.amount)) | MIN(sessions.COUNT(transactions)) | MIN(sessions.MAX(transactions.amount)) | MIN(sessions.MEAN(transactions.amount)) | MIN(sessions.NUM_UNIQUE(transactions.product_id)) | MIN(sessions.SKEW(transactions.amount)) | MIN(sessions.STD(transactions.amount)) | MIN(sessions.SUM(transactions.amount)) | MODE(sessions.DAY(session_start)) | MODE(sessions.MODE(transactions.product_id)) | MODE(sessions.MONTH(session_start)) | MODE(sessions.WEEKDAY(session_start)) | MODE(sessions.YEAR(session_start)) | NUM_UNIQUE(sessions.DAY(session_start)) | NUM_UNIQUE(sessions.MODE(transactions.product_id)) | NUM_UNIQUE(sessions.MONTH(session_start)) | NUM_UNIQUE(sessions.WEEKDAY(session_start)) | NUM_UNIQUE(sessions.YEAR(session_start)) | SKEW(sessions.COUNT(transactions)) | SKEW(sessions.MAX(transactions.amount)) | SKEW(sessions.MEAN(transactions.amount)) | SKEW(sessions.MIN(transactions.amount)) | SKEW(sessions.NUM_UNIQUE(transactions.product_id)) | SKEW(sessions.STD(transactions.amount)) | SKEW(sessions.SUM(transactions.amount)) | STD(sessions.COUNT(transactions)) | STD(sessions.MAX(transactions.amount)) | STD(sessions.MEAN(transactions.amount)) | STD(sessions.MIN(transactions.amount)) | STD(sessions.NUM_UNIQUE(transactions.product_id)) | STD(sessions.SKEW(transactions.amount)) | STD(sessions.SUM(transactions.amount)) | SUM(sessions.MAX(transactions.amount)) | SUM(sessions.MEAN(transactions.amount)) | SUM(sessions.MIN(transactions.amount)) | SUM(sessions.NUM_UNIQUE(transactions.product_id)) | SUM(sessions.SKEW(transactions.amount)) | SUM(sessions.STD(transactions.amount)) | MODE(transactions.sessions.device) | NUM_UNIQUE(transactions.sessions.device) | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| customer_id | time | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | 2014-01-01 04:00:00 | 60091 | 4 | tablet | 3 | 67 | 139.23 | 74.002836 | 5.81 | 4 | 5 | -0.006928 | 42.309717 | 4958.19 | 18 | 17 | 7 | 4 | 0 | 6 | 1994 | 2011 | 25.0 | 85.469167 | 8.74 | 5.0 | 0.234349 | 46.905665 | 1613.93 | 16.75 | 135.0100 | 76.150425 | 6.905 | 5.0 | -0.126261 | 42.393218 | 1239.5475 | 12.0 | 129.00 | 64.557200 | 5.0 | -0.830975 | 39.825249 | 1025.63 | 1 | 4 | 1 | 2 | 2014 | 1 | 3 | 1 | 1 | 1 | 1.614843 | -0.451371 | -0.233453 | 1.452325 | 0.0 | 1.235445 | 1.197406 | 5.678908 | 5.027226 | 10.426572 | 1.285833 | 0.0 | 0.500353 | 271.917637 | 540.04 | 304.601700 | 27.62 | 20.0 | -0.505043 | 169.572874 | tablet | 3 |
| 2 | 2014-01-01 04:00:00 | 13244 | 4 | desktop | 2 | 49 | 146.81 | 84.700000 | 12.07 | 4 | 5 | -0.134786 | 39.289512 | 4150.30 | 18 | 15 | 8 | 4 | 0 | 6 | 1986 | 2012 | 16.0 | 96.581000 | 56.46 | 5.0 | 0.295458 | 47.935920 | 1320.64 | 12.25 | 142.3225 | 85.197948 | 26.310 | 5.0 | 0.011293 | 39.315685 | 1037.5750 | 8.0 | 138.38 | 76.813125 | 5.0 | -0.455197 | 27.839228 | 634.84 | 1 | 2 | 1 | 2 | 2014 | 1 | 3 | 1 | 1 | 1 | -0.169238 | 0.459305 | 0.651941 | 1.815491 | 0.0 | -0.966834 | -0.823347 | 3.862210 | 3.470527 | 8.983533 | 20.424007 | 0.0 | 0.324809 | 307.743859 | 569.29 | 340.791792 | 105.24 | 20.0 | 0.045171 | 157.262738 | desktop | 2 |
| 3 | 2014-01-01 04:00:00 | 13244 | 1 | tablet | 1 | 15 | 146.31 | 62.791333 | 8.19 | 1 | 5 | 0.618455 | 47.264797 | 941.87 | 21 | 13 | 11 | 8 | 4 | 5 | 2003 | 2011 | 15.0 | 62.791333 | 8.19 | 5.0 | 0.618455 | 47.264797 | 941.87 | 15.00 | 146.3100 | 62.791333 | 8.190 | 5.0 | 0.618455 | 47.264797 | 941.8700 | 15.0 | 146.31 | 62.791333 | 5.0 | 0.618455 | 47.264797 | 941.87 | 1 | 1 | 1 | 2 | 2014 | 1 | 1 | 1 | 1 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 146.31 | 62.791333 | 8.19 | 5.0 | 0.618455 | 47.264797 | tablet | 1 |
Even though the entityset contains the complete transaction history for each customer, only data with a time index up to and including the cutoff time was used to calculate the features above.
Using a Cutoff Time DataFrame#
Oftentimes, the training examples for machine learning will come from different points in time. To specify a unique cutoff time for each row of the resulting feature matrix, we can pass a dataframe which includes one column for the instance id and another column for the corresponding cutoff time. These columns can be in any order, but they must be named properly. The column with the instance ids must either be named instance_id or have the same name as the target dataframe index. The
column with the cutoff time values must either be named time or have the same name as the target dataframe time_index.
The column names for the instance ids and the cutoff time values should be unambiguous. Passing a dataframe that contains both a column with the same name as the target dataframe index and a column named instance_id will result in an error. Similarly, if the cutoff time dataframe contains both a column with the same name as the target dataframe time_index and a column named time an error will be raised.
Note
Only the columns corresponding to the instance ids and the cutoff times are used to calculate features. Any additional columns passed through are appended to the resulting feature matrix. This is typically used to pass through machine learning labels to ensure that they stay aligned with the feature matrix.
[5]:
cutoff_times = pd.DataFrame()
cutoff_times["customer_id"] = [1, 2, 3, 1]
cutoff_times["time"] = pd.to_datetime(
["2014-1-1 04:00", "2014-1-1 05:00", "2014-1-1 06:00", "2014-1-1 08:00"]
)
cutoff_times["label"] = [True, True, False, True]
cutoff_times
fm, features = ft.dfs(
entityset=es,
target_dataframe_name="customers",
cutoff_time=cutoff_times,
cutoff_time_in_index=True,
)
fm
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
[5]:
| zip_code | COUNT(sessions) | MODE(sessions.device) | NUM_UNIQUE(sessions.device) | COUNT(transactions) | MAX(transactions.amount) | MEAN(transactions.amount) | MIN(transactions.amount) | MODE(transactions.product_id) | NUM_UNIQUE(transactions.product_id) | SKEW(transactions.amount) | STD(transactions.amount) | SUM(transactions.amount) | DAY(birthday) | DAY(join_date) | MONTH(birthday) | MONTH(join_date) | WEEKDAY(birthday) | WEEKDAY(join_date) | YEAR(birthday) | YEAR(join_date) | MAX(sessions.COUNT(transactions)) | MAX(sessions.MEAN(transactions.amount)) | MAX(sessions.MIN(transactions.amount)) | MAX(sessions.NUM_UNIQUE(transactions.product_id)) | MAX(sessions.SKEW(transactions.amount)) | MAX(sessions.STD(transactions.amount)) | MAX(sessions.SUM(transactions.amount)) | MEAN(sessions.COUNT(transactions)) | MEAN(sessions.MAX(transactions.amount)) | MEAN(sessions.MEAN(transactions.amount)) | MEAN(sessions.MIN(transactions.amount)) | MEAN(sessions.NUM_UNIQUE(transactions.product_id)) | MEAN(sessions.SKEW(transactions.amount)) | MEAN(sessions.STD(transactions.amount)) | MEAN(sessions.SUM(transactions.amount)) | MIN(sessions.COUNT(transactions)) | MIN(sessions.MAX(transactions.amount)) | MIN(sessions.MEAN(transactions.amount)) | MIN(sessions.NUM_UNIQUE(transactions.product_id)) | MIN(sessions.SKEW(transactions.amount)) | MIN(sessions.STD(transactions.amount)) | MIN(sessions.SUM(transactions.amount)) | MODE(sessions.DAY(session_start)) | MODE(sessions.MODE(transactions.product_id)) | MODE(sessions.MONTH(session_start)) | MODE(sessions.WEEKDAY(session_start)) | MODE(sessions.YEAR(session_start)) | NUM_UNIQUE(sessions.DAY(session_start)) | NUM_UNIQUE(sessions.MODE(transactions.product_id)) | NUM_UNIQUE(sessions.MONTH(session_start)) | NUM_UNIQUE(sessions.WEEKDAY(session_start)) | NUM_UNIQUE(sessions.YEAR(session_start)) | SKEW(sessions.COUNT(transactions)) | SKEW(sessions.MAX(transactions.amount)) | SKEW(sessions.MEAN(transactions.amount)) | SKEW(sessions.MIN(transactions.amount)) | SKEW(sessions.NUM_UNIQUE(transactions.product_id)) | SKEW(sessions.STD(transactions.amount)) | SKEW(sessions.SUM(transactions.amount)) | STD(sessions.COUNT(transactions)) | STD(sessions.MAX(transactions.amount)) | STD(sessions.MEAN(transactions.amount)) | STD(sessions.MIN(transactions.amount)) | STD(sessions.NUM_UNIQUE(transactions.product_id)) | STD(sessions.SKEW(transactions.amount)) | STD(sessions.SUM(transactions.amount)) | SUM(sessions.MAX(transactions.amount)) | SUM(sessions.MEAN(transactions.amount)) | SUM(sessions.MIN(transactions.amount)) | SUM(sessions.NUM_UNIQUE(transactions.product_id)) | SUM(sessions.SKEW(transactions.amount)) | SUM(sessions.STD(transactions.amount)) | MODE(transactions.sessions.device) | NUM_UNIQUE(transactions.sessions.device) | label | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| customer_id | time | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | 2014-01-01 04:00:00 | 60091 | 4 | tablet | 3 | 67 | 139.23 | 74.002836 | 5.81 | 4 | 5 | -0.006928 | 42.309717 | 4958.19 | 18 | 17 | 7 | 4 | 0 | 6 | 1994 | 2011 | 25.0 | 85.469167 | 8.74 | 5.0 | 0.234349 | 46.905665 | 1613.93 | 16.75 | 135.01000 | 76.150425 | 6.90500 | 5.0 | -0.126261 | 42.393218 | 1239.5475 | 12.0 | 129.00 | 64.557200 | 5.0 | -0.830975 | 39.825249 | 1025.63 | 1 | 4 | 1 | 2 | 2014 | 1 | 3 | 1 | 1 | 1 | 1.614843 | -0.451371 | -0.233453 | 1.452325 | 0.0 | 1.235445 | 1.197406 | 5.678908 | 5.027226 | 10.426572 | 1.285833 | 0.0 | 0.500353 | 271.917637 | 540.04 | 304.601700 | 27.62 | 20.0 | -0.505043 | 169.572874 | tablet | 3 | True |
| 2 | 2014-01-01 05:00:00 | 13244 | 5 | desktop | 2 | 62 | 146.81 | 83.149355 | 12.07 | 4 | 5 | -0.121811 | 38.047944 | 5155.26 | 18 | 15 | 8 | 4 | 0 | 6 | 1986 | 2012 | 16.0 | 96.581000 | 56.46 | 5.0 | 0.295458 | 47.935920 | 1320.64 | 12.40 | 137.62800 | 83.619281 | 25.41200 | 5.0 | -0.053949 | 38.197555 | 1031.0520 | 8.0 | 118.85 | 76.813125 | 5.0 | -0.455197 | 27.839228 | 634.84 | 1 | 2 | 1 | 2 | 2014 | 1 | 4 | 1 | 1 | 1 | -0.379092 | -1.814717 | 1.082192 | 1.959531 | 0.0 | -0.213518 | -0.667256 | 3.361547 | 10.919023 | 8.543351 | 17.801322 | 0.0 | 0.316873 | 266.912832 | 688.14 | 418.096407 | 127.06 | 25.0 | -0.269747 | 190.987775 | desktop | 2 | True |
| 3 | 2014-01-01 06:00:00 | 13244 | 4 | desktop | 2 | 44 | 146.31 | 65.174773 | 6.65 | 1 | 5 | 0.318315 | 40.349758 | 2867.69 | 21 | 13 | 11 | 8 | 4 | 5 | 2003 | 2011 | 17.0 | 91.760000 | 91.76 | 5.0 | 0.618455 | 47.264797 | 944.85 | 11.00 | 123.26750 | 72.742004 | 31.66500 | 4.0 | 0.286859 | 39.712232 | 716.9225 | 1.0 | 91.76 | 55.579412 | 1.0 | -0.289466 | 35.704680 | 91.76 | 1 | 1 | 1 | 2 | 2014 | 1 | 2 | 1 | 1 | 1 | -1.330938 | -1.060639 | 0.201588 | 1.874170 | -2.0 | 1.722323 | -1.977878 | 7.118052 | 22.808351 | 16.540737 | 40.508892 | 2.0 | 0.500999 | 417.557763 | 493.07 | 290.968018 | 126.66 | 16.0 | 0.860577 | 119.136697 | desktop | 2 | False |
| 1 | 2014-01-01 08:00:00 | 60091 | 8 | mobile | 3 | 126 | 139.43 | 71.631905 | 5.81 | 4 | 5 | 0.019698 | 40.442059 | 9025.62 | 18 | 17 | 7 | 4 | 0 | 6 | 1994 | 2011 | 25.0 | 88.755625 | 26.36 | 5.0 | 0.640252 | 46.905665 | 1613.93 | 15.75 | 132.24625 | 72.774140 | 9.82375 | 5.0 | -0.059515 | 39.093244 | 1128.2025 | 12.0 | 118.90 | 50.623125 | 5.0 | -1.038434 | 30.450261 | 809.97 | 1 | 4 | 1 | 2 | 2014 | 1 | 4 | 1 | 1 | 1 | 1.946018 | -0.780493 | -0.424949 | 2.440005 | 0.0 | -0.312355 | 0.778170 | 4.062019 | 7.322191 | 13.759314 | 6.954507 | 0.0 | 0.589386 | 279.510713 | 1057.97 | 582.193117 | 78.59 | 40.0 | -0.476122 | 312.745952 | mobile | 3 | True |
We can now see that every row of the feature matrix is calculated at the corresponding time in the cutoff time dataframe. Because we calculate each row at a different time, it is possible to have a repeat customer. In this case, we calculated the feature vector for customer 1 at both 04:00 and 08:00.
Training Window#
By default, all data up to and including the cutoff time is used. We can restrict the amount of historical data that is selected for calculations using a “training window.”
Here’s an example of using a two hour training window:
[6]:
window_fm, window_features = ft.dfs(
entityset=es,
target_dataframe_name="customers",
cutoff_time=cutoff_times,
cutoff_time_in_index=True,
training_window="2 hour",
)
window_fm
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
[6]:
| zip_code | COUNT(sessions) | MODE(sessions.device) | NUM_UNIQUE(sessions.device) | COUNT(transactions) | MAX(transactions.amount) | MEAN(transactions.amount) | MIN(transactions.amount) | MODE(transactions.product_id) | NUM_UNIQUE(transactions.product_id) | SKEW(transactions.amount) | STD(transactions.amount) | SUM(transactions.amount) | DAY(birthday) | DAY(join_date) | MONTH(birthday) | MONTH(join_date) | WEEKDAY(birthday) | WEEKDAY(join_date) | YEAR(birthday) | YEAR(join_date) | MAX(sessions.COUNT(transactions)) | MAX(sessions.MEAN(transactions.amount)) | MAX(sessions.MIN(transactions.amount)) | MAX(sessions.NUM_UNIQUE(transactions.product_id)) | MAX(sessions.SKEW(transactions.amount)) | MAX(sessions.STD(transactions.amount)) | MAX(sessions.SUM(transactions.amount)) | MEAN(sessions.COUNT(transactions)) | MEAN(sessions.MAX(transactions.amount)) | MEAN(sessions.MEAN(transactions.amount)) | MEAN(sessions.MIN(transactions.amount)) | MEAN(sessions.NUM_UNIQUE(transactions.product_id)) | MEAN(sessions.SKEW(transactions.amount)) | MEAN(sessions.STD(transactions.amount)) | MEAN(sessions.SUM(transactions.amount)) | MIN(sessions.COUNT(transactions)) | MIN(sessions.MAX(transactions.amount)) | MIN(sessions.MEAN(transactions.amount)) | MIN(sessions.NUM_UNIQUE(transactions.product_id)) | MIN(sessions.SKEW(transactions.amount)) | MIN(sessions.STD(transactions.amount)) | MIN(sessions.SUM(transactions.amount)) | MODE(sessions.DAY(session_start)) | MODE(sessions.MODE(transactions.product_id)) | MODE(sessions.MONTH(session_start)) | MODE(sessions.WEEKDAY(session_start)) | MODE(sessions.YEAR(session_start)) | NUM_UNIQUE(sessions.DAY(session_start)) | NUM_UNIQUE(sessions.MODE(transactions.product_id)) | NUM_UNIQUE(sessions.MONTH(session_start)) | NUM_UNIQUE(sessions.WEEKDAY(session_start)) | NUM_UNIQUE(sessions.YEAR(session_start)) | SKEW(sessions.COUNT(transactions)) | SKEW(sessions.MAX(transactions.amount)) | SKEW(sessions.MEAN(transactions.amount)) | SKEW(sessions.MIN(transactions.amount)) | SKEW(sessions.NUM_UNIQUE(transactions.product_id)) | SKEW(sessions.STD(transactions.amount)) | SKEW(sessions.SUM(transactions.amount)) | STD(sessions.COUNT(transactions)) | STD(sessions.MAX(transactions.amount)) | STD(sessions.MEAN(transactions.amount)) | STD(sessions.MIN(transactions.amount)) | STD(sessions.NUM_UNIQUE(transactions.product_id)) | STD(sessions.SKEW(transactions.amount)) | STD(sessions.SUM(transactions.amount)) | SUM(sessions.MAX(transactions.amount)) | SUM(sessions.MEAN(transactions.amount)) | SUM(sessions.MIN(transactions.amount)) | SUM(sessions.NUM_UNIQUE(transactions.product_id)) | SUM(sessions.SKEW(transactions.amount)) | SUM(sessions.STD(transactions.amount)) | MODE(transactions.sessions.device) | NUM_UNIQUE(transactions.sessions.device) | label | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| customer_id | time | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | 2014-01-01 04:00:00 | 60091 | 2 | desktop | 2 | 27 | 139.09 | 76.950370 | 5.81 | 4 | 5 | -0.187686 | 43.772157 | 2077.66 | 18 | 17 | 7 | 4 | 0 | 6 | 1994 | 2011 | 15.0 | 85.469167 | 6.78 | 5.0 | 0.226337 | 46.905665 | 1052.03 | 13.500000 | 135.905000 | 77.802250 | 6.295000 | 5.000000 | -0.302319 | 43.365457 | 1038.830000 | 12.0 | 132.72 | 70.135333 | 5.0 | -0.830975 | 39.825249 | 1025.63 | 1 | 1 | 1 | 2 | 2014 | 1 | 2 | 1 | 1 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2.121320 | 4.504270 | 10.842658 | 0.685894 | 0.000000 | 0.747633 | 18.667619 | 271.81 | 155.604500 | 12.59 | 10.0 | -0.604638 | 86.730914 | desktop | 2 | True |
| 2 | 2014-01-01 05:00:00 | 13244 | 3 | desktop | 2 | 31 | 146.81 | 84.051935 | 12.07 | 4 | 5 | -0.198611 | 36.077146 | 2605.61 | 18 | 15 | 8 | 4 | 0 | 6 | 1986 | 2012 | 13.0 | 96.581000 | 56.46 | 5.0 | 0.130019 | 47.935920 | 1004.96 | 10.333333 | 134.680000 | 84.413538 | 30.116667 | 5.000000 | -0.036670 | 36.500062 | 868.536667 | 8.0 | 118.85 | 77.304615 | 5.0 | -0.314918 | 27.839228 | 634.84 | 1 | 1 | 1 | 2 | 2014 | 1 | 3 | 1 | 1 | 1 | 0.585583 | -1.083626 | 1.659252 | 1.397956 | 0.000000 | 1.121470 | -1.660092 | 2.516611 | 14.342521 | 10.587085 | 23.329038 | 0.000000 | 0.242542 | 203.331699 | 404.04 | 253.240615 | 90.35 | 15.0 | -0.110009 | 109.500185 | desktop | 2 | True |
| 3 | 2014-01-01 06:00:00 | 13244 | 3 | desktop | 1 | 29 | 128.26 | 66.407586 | 6.65 | 1 | 5 | 0.110145 | 37.130891 | 1925.82 | 21 | 13 | 11 | 8 | 4 | 5 | 2003 | 2011 | 17.0 | 91.760000 | 91.76 | 5.0 | 0.531588 | 36.167220 | 944.85 | 9.666667 | 115.586667 | 76.058895 | 39.490000 | 3.666667 | 0.121061 | 35.935950 | 641.940000 | 1.0 | 91.76 | 55.579412 | 1.0 | -0.289466 | 35.704680 | 91.76 | 1 | 1 | 1 | 2 | 2014 | 1 | 2 | 1 | 1 | 1 | -0.722109 | -1.721498 | -1.081879 | 1.566223 | -1.732051 | NaN | -1.705607 | 8.082904 | 20.648490 | 18.557570 | 45.761028 | 2.309401 | 0.580573 | 477.281339 | 346.76 | 228.176684 | 118.47 | 11.0 | 0.242122 | 71.871900 | desktop | 1 | False |
| 1 | 2014-01-01 08:00:00 | 60091 | 3 | mobile | 2 | 47 | 139.43 | 66.471277 | 5.91 | 4 | 5 | 0.047120 | 38.952172 | 3124.15 | 18 | 17 | 7 | 4 | 0 | 6 | 1994 | 2011 | 16.0 | 88.755625 | 11.62 | 5.0 | 0.640252 | 44.354104 | 1420.09 | 15.666667 | 128.146667 | 66.328250 | 8.203333 | 5.000000 | -0.001146 | 35.709633 | 1041.383333 | 15.0 | 118.90 | 50.623125 | 5.0 | -1.038434 | 30.450261 | 809.97 | 1 | 1 | 1 | 2 | 2014 | 1 | 3 | 1 | 1 | 1 | -1.732051 | 0.846298 | 1.344879 | 1.443486 | 0.000000 | 1.612576 | 1.606791 | 0.577350 | 10.415432 | 19.935229 | 3.016195 | 0.000000 | 0.906666 | 330.655558 | 384.44 | 198.984750 | 24.61 | 15.0 | -0.003438 | 107.128899 | mobile | 2 | True |
We can see that that the counts for the same feature are lower after we shorten the training window:
[7]:
fm[["COUNT(transactions)"]]
window_fm[["COUNT(transactions)"]]
[7]:
| COUNT(transactions) | ||
|---|---|---|
| customer_id | time | |
| 1 | 2014-01-01 04:00:00 | 27 |
| 2 | 2014-01-01 05:00:00 | 31 |
| 3 | 2014-01-01 06:00:00 | 29 |
| 1 | 2014-01-01 08:00:00 | 47 |
Setting a Last Time Index#
The training window in Featuretools limits the amount of past data that can be used while calculating a particular feature vector. A row in the dataframe is filtered out if the value of its time index is either before or after the training window. This works for dataframes where a row occurs at a single point in time. However, a row can sometimes exist for a duration.
For example, a customer’s session has multiple transactions which can happen at different points in time. If we are trying to count the number of sessions a user has in a given time period, we often want to count all the sessions that had any transaction during the training window. To accomplish this, we need to not only know when a session starts, but also when it ends. The last time that an instance appears in the data is stored in the _ft_last_time column on the dataframe. We can
compare the time index and the last time index of the sessions dataframe above:
[8]:
last_time_index_col = es["sessions"].ww.metadata.get("last_time_index")
es["sessions"][["session_start", last_time_index_col]].head()
[8]:
| session_start | _ft_last_time | |
|---|---|---|
| 1 | 2014-01-01 00:00:00 | 2014-01-01 00:16:15 |
| 2 | 2014-01-01 00:17:20 | 2014-01-01 00:27:05 |
| 3 | 2014-01-01 00:28:10 | 2014-01-01 00:43:20 |
| 4 | 2014-01-01 00:44:25 | 2014-01-01 01:10:25 |
| 5 | 2014-01-01 01:11:30 | 2014-01-01 01:22:20 |
Featuretools can automatically add last time indexes to every DataFrame in an Entityset by running EntitySet.add_last_time_indexes(). When using a training window, if a last_time_index has been set, Featuretools will check to see if the last_time_index is after the start of the training window. That, combined with the cutoff time, allows DFS to discover which data is relevant for a given training window.
Excluding data at cutoff times#
The cutoff_time is the last point in time where data can be used for feature
calculation. If you don’t want to use the data at the cutoff time in feature
calculation, you can exclude that data by setting include_cutoff_time to
False in featuretools.dfs() or featuretools.calculate_feature_matrix().
If you set it to True (the default behavior), data from the cutoff time point
will be used.
Setting include_cutoff_time to False also impacts how data at the edges of training windows are included or excluded. Take this slice of data as an example:
[9]:
df = es["transactions"]
df[df["session_id"] == 1].head()
[9]:
| transaction_id | session_id | transaction_time | product_id | amount | _ft_last_time | |
|---|---|---|---|---|---|---|
| 10 | 10 | 1 | 2014-01-01 00:00:00 | 5 | 127.64 | 2014-01-01 00:00:00 |
| 2 | 2 | 1 | 2014-01-01 00:01:05 | 2 | 109.48 | 2014-01-01 00:01:05 |
| 438 | 438 | 1 | 2014-01-01 00:02:10 | 3 | 95.06 | 2014-01-01 00:02:10 |
| 192 | 192 | 1 | 2014-01-01 00:03:15 | 4 | 78.92 | 2014-01-01 00:03:15 |
| 271 | 271 | 1 | 2014-01-01 00:04:20 | 3 | 31.54 | 2014-01-01 00:04:20 |
Looking at the data, transactions occur every 65 seconds. To check how include_cutoff_time effects training windows, we can calculate features at the time of a transaction while using a 65 second training window. This creates a training window with a transaction at both endpoints of the window. For this example, we’ll find the sum of all transactions for session id 1 that are in the training window.
[10]:
from featuretools.primitives import Sum
sum_log = ft.Feature(
es["transactions"].ww["amount"],
parent_dataframe_name="sessions",
primitive=Sum,
)
cutoff_time = pd.DataFrame(
{
"session_id": [1],
"time": ["2014-01-01 00:04:20"],
}
).astype({"time": "datetime64[ns]"})
With include_cutoff_time=True, the oldest point in the training window (2014-01-01 00:03:15) is excluded and the cutoff time point is included. This means only transaction 371 is in the training window, so the sum of all transaction amounts is 31.54
[11]:
# Case1. include_cutoff_time = True
actual = ft.calculate_feature_matrix(
features=[sum_log],
entityset=es,
cutoff_time=cutoff_time,
cutoff_time_in_index=True,
training_window="65 seconds",
include_cutoff_time=True,
)
actual
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
[11]:
| SUM(transactions.amount) | ||
|---|---|---|
| session_id | time | |
| 1 | 2014-01-01 00:04:20 | 31.54 |
Whereas with include_cutoff_time=False, the oldest point in the window is included and the cutoff time point is excluded. So in this case transaction 116 is included and transaction 371 is exluded, and the sum is 78.92
[12]:
# Case2. include_cutoff_time = False
actual = ft.calculate_feature_matrix(
features=[sum_log],
entityset=es,
cutoff_time=cutoff_time,
cutoff_time_in_index=True,
training_window="65 seconds",
include_cutoff_time=False,
)
actual
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
[12]:
| SUM(transactions.amount) | ||
|---|---|---|
| session_id | time | |
| 1 | 2014-01-01 00:04:20 | 78.92 |
Approximating Features by Rounding Cutoff Times#
For each unique cutoff time, Featuretools must perform operations to select the data that’s valid for computations. If there are a large number of unique cutoff times relative to the number of instances for which we are calculating features, the time spent filtering data can add up. By reducing the number of unique cutoff times, we minimize the overhead from searching for and extracting data for feature calculations.
One way to decrease the number of unique cutoff times is to round cutoff times to an earlier point in time. An earlier cutoff time is always valid for predictive modeling — it just means we’re not using some of the data we could potentially use while calculating that feature. So, we gain computational speed by losing a small amount of information.
To understand when an approximation is useful, consider calculating features for a model to predict fraudulent credit card transactions. In this case, an important feature might be, “the average transaction amount for this card in the past”. While this value can change every time there is a new transaction, updating it less frequently might not impact accuracy.
Note
The bank BBVA used approximation when building a predictive model for credit card fraud using Featuretools. For more details, see the “Real-time deployment considerations” section of the white paper describing the work involved.
The frequency of approximation is controlled using the approximate parameter to featuretools.dfs() or featuretools.calculate_feature_matrix(). For example, the following code would approximate aggregation features at 1 day intervals:
..
fm = ft.calculate_feature_matrix(features=features,
entityset=es_transactions,
cutoff_time=ct_transactions,
approximate="1 day")
In this computation, features that can be approximated will be calculated at 1 day intervals, while features that cannot be approximated (e.g “where did this transaction occur?”) will be calculated at the exact cutoff time.
Secondary Time Index#
It is sometimes the case that information in a dataset is updated or added after a row has been created. This means that certain columns may actually become known after the time index for a row. Rather than drop those columns to avoid leaking information, we can create a secondary time index to indicate when those columns become known.
The Flights entityset is a good example of a dataset where column values in a row become known at different times. Each trip is recorded in the trip_logs dataframe, and has many times associated with it.
[14]:
es_flight = ft.demo.load_flight(nrows=100)
es_flight
es_flight["trip_logs"].head(3)
Downloading data ...
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/demo/flight.py:291: PerformanceWarning: Adding/subtracting object-dtype array to TimedeltaArray not vectorized.
clean_data.loc[:, "dep_time"] = clean_data["scheduled_dep_time"] + pd.to_timedelta(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/demo/flight.py:296: PerformanceWarning: Adding/subtracting object-dtype array to TimedeltaArray not vectorized.
clean_data.loc[:, "arr_time"] = clean_data["dep_time"] + pd.to_timedelta(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/demo/flight.py:302: PerformanceWarning: Adding/subtracting object-dtype array to TimedeltaArray not vectorized.
clean_data["scheduled_dep_time"] + clean_data["scheduled_elapsed_time"]
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/logical_types.py:841: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
series = series.replace(ww.config.get_option("nan_values"), np.nan)
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/logical_types.py:841: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
series = series.replace(ww.config.get_option("nan_values"), np.nan)
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/type_sys/utils.py:33: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
pd.to_datetime(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/logical_types.py:841: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
series = series.replace(ww.config.get_option("nan_values"), np.nan)
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/logical_types.py:841: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
series = series.replace(ww.config.get_option("nan_values"), np.nan)
[14]:
| trip_log_id | flight_id | date_scheduled | scheduled_dep_time | scheduled_arr_time | dep_time | arr_time | dep_delay | taxi_out | taxi_in | arr_delay | diverted | scheduled_elapsed_time | air_time | distance | carrier_delay | weather_delay | national_airspace_delay | security_delay | late_aircraft_delay | canceled | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 30 | 30 | AA-494:RSW->CLT | 2016-09-03 | 2017-01-01 13:14:00 | 2017-01-01 15:05:00 | 2017-01-01 13:03:00 | 2017-01-01 14:53:00 | -11.0 | 12.0 | 10.0 | -12.0 | False | 0 days 01:51:00 | 88.0 | 600.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | False |
| 38 | 38 | AA-495:ATL->PHX | 2016-09-03 | 2017-01-01 11:30:00 | 2017-01-01 15:40:00 | 2017-01-01 11:24:00 | 2017-01-01 15:41:00 | -6.0 | 28.0 | 5.0 | 1.0 | False | 0 days 04:10:00 | 224.0 | 1587.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | False |
| 46 | 46 | AA-495:CLT->ATL | 2016-09-03 | 2017-01-01 09:25:00 | 2017-01-01 10:42:00 | 2017-01-01 09:23:00 | 2017-01-01 10:39:00 | -2.0 | 18.0 | 8.0 | -3.0 | False | 0 days 01:17:00 | 50.0 | 226.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | False |
For every trip log, the time index is date_scheduled, which is when the airline decided on the scheduled departure and arrival times, as well as what route will be flown. We don’t know the rest of the information about the actual departure/arrival times and the details of any delay at this time. However, it is possible to know everything about how a trip went after it has arrived, so we can use that information at any time after the flight lands.
Using a secondary time index, we can indicate to Featuretools which columns in our flight logs are known at the time the flight is scheduled, plus which are known at the time the flight lands.

In Featuretools, when adding the dataframe to the EntitySet, we set the secondary time index to be the arrival time like this:
es = ft.EntitySet('Flight Data')
arr_time_columns = ['arr_delay', 'dep_delay', 'carrier_delay', 'weather_delay',
'national_airspace_delay', 'security_delay',
'late_aircraft_delay', 'canceled', 'diverted',
'taxi_in', 'taxi_out', 'air_time', 'dep_time']
es.add_dataframe(
dataframe_name='trip_logs',
dataframe=data,
index='trip_log_id',
make_index=True,
time_index='date_scheduled',
secondary_time_index={'arr_time': arr_time_columns})
By setting a secondary time index, we can still use the delay information from a row, but only when it becomes known.
Hint
It’s often a good idea to use a secondary time index if your entityset has inline labels. If you know when the label would be valid for use, it’s possible to automatically create very predictive features using historical labels.
Flight Predictions#
Let’s make some features at varying times using the flight example described above. Trip 14 is a flight from CLT to PHX on January 31, 2017 and trip 92 is a flight from PIT to DFW on January 1. We can set any cutoff time before the flight is scheduled to depart, emulating how we would make the prediction at that point in time.
We set two cutoff times for trip 14 at two different times: one which is more than a month before the flight and another which is only 5 days before. For trip 92, we’ll only set one cutoff time, three days before it is scheduled to leave.

Our cutoff time dataframe looks like this:
[15]:
ct_flight = pd.DataFrame()
ct_flight["trip_log_id"] = [14, 14, 92]
ct_flight["time"] = pd.to_datetime(["2016-12-28", "2017-1-25", "2016-12-28"])
ct_flight["label"] = [True, True, False]
ct_flight
[15]:
| trip_log_id | time | label | |
|---|---|---|---|
| 0 | 14 | 2016-12-28 | True |
| 1 | 14 | 2017-01-25 | True |
| 2 | 92 | 2016-12-28 | False |
Now, let’s calculate the feature matrix:
[16]:
fm, features = ft.dfs(
entityset=es_flight,
target_dataframe_name="trip_logs",
cutoff_time=ct_flight,
cutoff_time_in_index=True,
agg_primitives=["max"],
trans_primitives=["month"],
)
fm[
[
"flights.origin",
"flights.dest",
"label",
"flights.MAX(trip_logs.arr_delay)",
"MONTH(scheduled_dep_time)",
]
]
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/entityset/entityset.py:1455: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value 'nan' has dtype incompatible with bool, please explicitly cast to a compatible dtype first.
df.loc[mask, columns] = np.nan
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/entityset/entityset.py:1455: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value 'nan' has dtype incompatible with bool, please explicitly cast to a compatible dtype first.
df.loc[mask, columns] = np.nan
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/entityset/entityset.py:1455: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value 'nan' has dtype incompatible with bool, please explicitly cast to a compatible dtype first.
df.loc[mask, columns] = np.nan
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/entityset/entityset.py:1455: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value 'nan' has dtype incompatible with bool, please explicitly cast to a compatible dtype first.
df.loc[mask, columns] = np.nan
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/entityset/entityset.py:1455: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value 'nan' has dtype incompatible with bool, please explicitly cast to a compatible dtype first.
df.loc[mask, columns] = np.nan
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/entityset/entityset.py:1455: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value 'nan' has dtype incompatible with bool, please explicitly cast to a compatible dtype first.
df.loc[mask, columns] = np.nan
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/entityset/entityset.py:1455: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value 'nan' has dtype incompatible with bool, please explicitly cast to a compatible dtype first.
df.loc[mask, columns] = np.nan
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/entityset/entityset.py:1455: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value 'nan' has dtype incompatible with bool, please explicitly cast to a compatible dtype first.
df.loc[mask, columns] = np.nan
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/logical_types.py:841: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
series = series.replace(ww.config.get_option("nan_values"), np.nan)
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/logical_types.py:841: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
series = series.replace(ww.config.get_option("nan_values"), np.nan)
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/logical_types.py:841: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
series = series.replace(ww.config.get_option("nan_values"), np.nan)
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/woodwork/logical_types.py:841: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
series = series.replace(ww.config.get_option("nan_values"), np.nan)
[16]:
| flights.origin | flights.dest | label | flights.MAX(trip_logs.arr_delay) | MONTH(scheduled_dep_time) | ||
|---|---|---|---|---|---|---|
| trip_log_id | time | |||||
| 14 | 2016-12-28 | CLT | PHX | True | NaN | 1 |
| 2017-01-25 | CLT | PHX | True | 33.0 | 1 | |
| 92 | 2016-12-28 | PIT | DFW | False | NaN | 1 |
Let’s understand the output:
A row was made for every id-time pair in
ct_flight, which is returned as the index of the feature matrix.The output was sorted by cutoff time. Because of the sorting, it’s often helpful to pass in a label with the cutoff time dataframe so that it will remain sorted in the same fashion as the feature matrix. Any additional columns beyond
idandcutoff_timewill not be used for making features.The column
flights.MAX(trip_logs.arr_delay)is not always defined. It can only have any real values when there are historical flights to aggregate. Notice that, for trip14, there wasn’t any historical data when we made the feature a month in advance, but there were flights to aggregate when we shortened it to 5 days. These are powerful features that are often excluded in manual processes because of how hard they are to make.
Creating and Flattening a Feature Tensor#
The featuretools.make_temporal_cutoffs() function generates a series of equally spaced cutoff times from a given set of cutoff times and instance ids.
This function can be paired with DFS to create and flatten a feature tensor rather than making multiple feature matrices at different delays.
The function takes in the the following parameters:
instance_ids (list, pd.Series, or np.ndarray): A list of instances.cutoffs (list, pd.Series, or np.ndarray): An associated list of cutoff times.window_size (str or pandas.DateOffset): The amount of time between each cutoff time in the created time series.start (datetime.datetime or pd.Timestamp): The first cutoff time in the created time series.num_windows (int): The number of cutoff times to create in the created time series.
Only two of the three options window_size, start, and num_windows need to be specified to uniquely determine an equally-spaced set of cutoff times at which to compute each instance.
If your cutoff times are the ones used above:
[17]:
cutoff_times
[17]:
| customer_id | time | label | |
|---|---|---|---|
| 0 | 1 | 2014-01-01 04:00:00 | True |
| 1 | 2 | 2014-01-01 05:00:00 | True |
| 2 | 3 | 2014-01-01 06:00:00 | False |
| 3 | 1 | 2014-01-01 08:00:00 | True |
Then passing in window_size='1h' and num_windows=2 makes one row an hour over the last two hours to produce the following new dataframe. The result can be directly passed into DFS to make features at the different time points.
[18]:
temporal_cutoffs = ft.make_temporal_cutoffs(
cutoff_times["customer_id"], cutoff_times["time"], window_size="1h", num_windows=2
)
temporal_cutoffs
fm, features = ft.dfs(
entityset=es,
target_dataframe_name="customers",
cutoff_time=temporal_cutoffs,
cutoff_time_in_index=True,
)
fm
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function max at 0x7f99e0108790> is currently using SeriesGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function sum at 0x7f99e0108160> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function std at 0x7f99e010d1f0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function mean at 0x7f99e010d0d0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
to_merge = base_frame.groupby(
/home/docs/checkouts/readthedocs.org/user_builds/feature-labs-inc-featuretools/envs/stable/lib/python3.9/site-packages/featuretools/computational_backends/feature_set_calculator.py:781: FutureWarning: The provided callable <function min at 0x7f99e01088b0> is currently using SeriesGroupBy.min. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "min" instead.
to_merge = base_frame.groupby(
[18]:
| zip_code | COUNT(sessions) | MODE(sessions.device) | NUM_UNIQUE(sessions.device) | COUNT(transactions) | MAX(transactions.amount) | MEAN(transactions.amount) | MIN(transactions.amount) | MODE(transactions.product_id) | NUM_UNIQUE(transactions.product_id) | SKEW(transactions.amount) | STD(transactions.amount) | SUM(transactions.amount) | DAY(birthday) | DAY(join_date) | MONTH(birthday) | MONTH(join_date) | WEEKDAY(birthday) | WEEKDAY(join_date) | YEAR(birthday) | YEAR(join_date) | MAX(sessions.COUNT(transactions)) | MAX(sessions.MEAN(transactions.amount)) | MAX(sessions.MIN(transactions.amount)) | MAX(sessions.NUM_UNIQUE(transactions.product_id)) | MAX(sessions.SKEW(transactions.amount)) | MAX(sessions.STD(transactions.amount)) | MAX(sessions.SUM(transactions.amount)) | MEAN(sessions.COUNT(transactions)) | MEAN(sessions.MAX(transactions.amount)) | MEAN(sessions.MEAN(transactions.amount)) | MEAN(sessions.MIN(transactions.amount)) | MEAN(sessions.NUM_UNIQUE(transactions.product_id)) | MEAN(sessions.SKEW(transactions.amount)) | MEAN(sessions.STD(transactions.amount)) | MEAN(sessions.SUM(transactions.amount)) | MIN(sessions.COUNT(transactions)) | MIN(sessions.MAX(transactions.amount)) | MIN(sessions.MEAN(transactions.amount)) | MIN(sessions.NUM_UNIQUE(transactions.product_id)) | MIN(sessions.SKEW(transactions.amount)) | MIN(sessions.STD(transactions.amount)) | MIN(sessions.SUM(transactions.amount)) | MODE(sessions.DAY(session_start)) | MODE(sessions.MODE(transactions.product_id)) | MODE(sessions.MONTH(session_start)) | MODE(sessions.WEEKDAY(session_start)) | MODE(sessions.YEAR(session_start)) | NUM_UNIQUE(sessions.DAY(session_start)) | NUM_UNIQUE(sessions.MODE(transactions.product_id)) | NUM_UNIQUE(sessions.MONTH(session_start)) | NUM_UNIQUE(sessions.WEEKDAY(session_start)) | NUM_UNIQUE(sessions.YEAR(session_start)) | SKEW(sessions.COUNT(transactions)) | SKEW(sessions.MAX(transactions.amount)) | SKEW(sessions.MEAN(transactions.amount)) | SKEW(sessions.MIN(transactions.amount)) | SKEW(sessions.NUM_UNIQUE(transactions.product_id)) | SKEW(sessions.STD(transactions.amount)) | SKEW(sessions.SUM(transactions.amount)) | STD(sessions.COUNT(transactions)) | STD(sessions.MAX(transactions.amount)) | STD(sessions.MEAN(transactions.amount)) | STD(sessions.MIN(transactions.amount)) | STD(sessions.NUM_UNIQUE(transactions.product_id)) | STD(sessions.SKEW(transactions.amount)) | STD(sessions.SUM(transactions.amount)) | SUM(sessions.MAX(transactions.amount)) | SUM(sessions.MEAN(transactions.amount)) | SUM(sessions.MIN(transactions.amount)) | SUM(sessions.NUM_UNIQUE(transactions.product_id)) | SUM(sessions.SKEW(transactions.amount)) | SUM(sessions.STD(transactions.amount)) | MODE(transactions.sessions.device) | NUM_UNIQUE(transactions.sessions.device) | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| customer_id | time | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | 2014-01-01 03:00:00 | 60091 | 3 | desktop | 3 | 55 | 139.23 | 71.501091 | 5.81 | 1 | 5 | 0.140387 | 42.769602 | 3932.56 | 18 | 17 | 7 | 4 | 0 | 6 | 1994 | 2011 | 25.0 | 84.440000 | 8.74 | 5.0 | 0.234349 | 46.905665 | 1613.93 | 18.333333 | 133.650000 | 73.044178 | 6.946667 | 5.0 | 0.108644 | 43.249208 | 1310.853333 | 15.0 | 129.00 | 64.557200 | 5.0 | -0.134754 | 40.187205 | 1052.03 | 1 | 1 | 1 | 2 | 2014 | 1 | 3 | 1 | 1 | 1 | 1.732051 | 0.782152 | 1.173675 | 1.552040 | 0.0 | 0.763052 | 0.685199 | 5.773503 | 5.178021 | 10.255607 | 1.571507 | 0.0 | 0.210827 | 283.551883 | 400.95 | 219.132533 | 20.84 | 15.0 | 0.325932 | 129.747625 | mobile | 3 |
| 2014-01-01 04:00:00 | 60091 | 4 | tablet | 3 | 67 | 139.23 | 74.002836 | 5.81 | 4 | 5 | -0.006928 | 42.309717 | 4958.19 | 18 | 17 | 7 | 4 | 0 | 6 | 1994 | 2011 | 25.0 | 85.469167 | 8.74 | 5.0 | 0.234349 | 46.905665 | 1613.93 | 16.750000 | 135.010000 | 76.150425 | 6.905000 | 5.0 | -0.126261 | 42.393218 | 1239.547500 | 12.0 | 129.00 | 64.557200 | 5.0 | -0.830975 | 39.825249 | 1025.63 | 1 | 4 | 1 | 2 | 2014 | 1 | 3 | 1 | 1 | 1 | 1.614843 | -0.451371 | -0.233453 | 1.452325 | 0.0 | 1.235445 | 1.197406 | 5.678908 | 5.027226 | 10.426572 | 1.285833 | 0.0 | 0.500353 | 271.917637 | 540.04 | 304.601700 | 27.62 | 20.0 | -0.505043 | 169.572874 | tablet | 3 | |
| 2 | 2014-01-01 04:00:00 | 13244 | 4 | desktop | 2 | 49 | 146.81 | 84.700000 | 12.07 | 4 | 5 | -0.134786 | 39.289512 | 4150.30 | 18 | 15 | 8 | 4 | 0 | 6 | 1986 | 2012 | 16.0 | 96.581000 | 56.46 | 5.0 | 0.295458 | 47.935920 | 1320.64 | 12.250000 | 142.322500 | 85.197948 | 26.310000 | 5.0 | 0.011293 | 39.315685 | 1037.575000 | 8.0 | 138.38 | 76.813125 | 5.0 | -0.455197 | 27.839228 | 634.84 | 1 | 2 | 1 | 2 | 2014 | 1 | 3 | 1 | 1 | 1 | -0.169238 | 0.459305 | 0.651941 | 1.815491 | 0.0 | -0.966834 | -0.823347 | 3.862210 | 3.470527 | 8.983533 | 20.424007 | 0.0 | 0.324809 | 307.743859 | 569.29 | 340.791792 | 105.24 | 20.0 | 0.045171 | 157.262738 | desktop | 2 |
| 2014-01-01 05:00:00 | 13244 | 5 | desktop | 2 | 62 | 146.81 | 83.149355 | 12.07 | 4 | 5 | -0.121811 | 38.047944 | 5155.26 | 18 | 15 | 8 | 4 | 0 | 6 | 1986 | 2012 | 16.0 | 96.581000 | 56.46 | 5.0 | 0.295458 | 47.935920 | 1320.64 | 12.400000 | 137.628000 | 83.619281 | 25.412000 | 5.0 | -0.053949 | 38.197555 | 1031.052000 | 8.0 | 118.85 | 76.813125 | 5.0 | -0.455197 | 27.839228 | 634.84 | 1 | 2 | 1 | 2 | 2014 | 1 | 4 | 1 | 1 | 1 | -0.379092 | -1.814717 | 1.082192 | 1.959531 | 0.0 | -0.213518 | -0.667256 | 3.361547 | 10.919023 | 8.543351 | 17.801322 | 0.0 | 0.316873 | 266.912832 | 688.14 | 418.096407 | 127.06 | 25.0 | -0.269747 | 190.987775 | desktop | 2 | |
| 3 | 2014-01-01 05:00:00 | 13244 | 2 | desktop | 2 | 32 | 146.31 | 58.960000 | 6.65 | 1 | 5 | 0.637074 | 41.199361 | 1886.72 | 21 | 13 | 11 | 8 | 4 | 5 | 2003 | 2011 | 17.0 | 62.791333 | 8.19 | 5.0 | 0.618455 | 47.264797 | 944.85 | 16.000000 | 136.525000 | 59.185373 | 7.420000 | 5.0 | 0.575022 | 41.716008 | 943.360000 | 15.0 | 126.74 | 55.579412 | 5.0 | 0.531588 | 36.167220 | 941.87 | 1 | 1 | 1 | 2 | 2014 | 1 | 1 | 1 | 1 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 1.414214 | 13.838080 | 5.099599 | 1.088944 | 0.0 | 0.061424 | 2.107178 | 273.05 | 118.370745 | 14.84 | 10.0 | 1.150043 | 83.432017 | desktop | 2 |
| 2014-01-01 06:00:00 | 13244 | 4 | desktop | 2 | 44 | 146.31 | 65.174773 | 6.65 | 1 | 5 | 0.318315 | 40.349758 | 2867.69 | 21 | 13 | 11 | 8 | 4 | 5 | 2003 | 2011 | 17.0 | 91.760000 | 91.76 | 5.0 | 0.618455 | 47.264797 | 944.85 | 11.000000 | 123.267500 | 72.742004 | 31.665000 | 4.0 | 0.286859 | 39.712232 | 716.922500 | 1.0 | 91.76 | 55.579412 | 1.0 | -0.289466 | 35.704680 | 91.76 | 1 | 1 | 1 | 2 | 2014 | 1 | 2 | 1 | 1 | 1 | -1.330938 | -1.060639 | 0.201588 | 1.874170 | -2.0 | 1.722323 | -1.977878 | 7.118052 | 22.808351 | 16.540737 | 40.508892 | 2.0 | 0.500999 | 417.557763 | 493.07 | 290.968018 | 126.66 | 16.0 | 0.860577 | 119.136697 | desktop | 2 | |
| 1 | 2014-01-01 07:00:00 | 60091 | 7 | tablet | 3 | 110 | 139.43 | 69.141182 | 5.81 | 4 | 5 | 0.149908 | 41.018896 | 7605.53 | 18 | 17 | 7 | 4 | 0 | 6 | 1994 | 2011 | 25.0 | 85.469167 | 26.36 | 5.0 | 0.640252 | 46.905665 | 1613.93 | 15.714286 | 133.122857 | 70.491070 | 9.567143 | 5.0 | 0.080330 | 40.060203 | 1086.504286 | 12.0 | 118.90 | 50.623125 | 5.0 | -0.830975 | 30.450261 | 809.97 | 1 | 1 | 1 | 2 | 2014 | 1 | 4 | 1 | 1 | 1 | 1.927658 | -1.277394 | -0.282093 | 2.552328 | 0.0 | -0.755846 | 1.377768 | 4.386125 | 7.441648 | 13.123365 | 7.470707 | 0.0 | 0.471955 | 273.713405 | 931.86 | 493.437492 | 66.97 | 35.0 | 0.562312 | 280.421418 | tablet | 3 |
| 2014-01-01 08:00:00 | 60091 | 8 | mobile | 3 | 126 | 139.43 | 71.631905 | 5.81 | 4 | 5 | 0.019698 | 40.442059 | 9025.62 | 18 | 17 | 7 | 4 | 0 | 6 | 1994 | 2011 | 25.0 | 88.755625 | 26.36 | 5.0 | 0.640252 | 46.905665 | 1613.93 | 15.750000 | 132.246250 | 72.774140 | 9.823750 | 5.0 | -0.059515 | 39.093244 | 1128.202500 | 12.0 | 118.90 | 50.623125 | 5.0 | -1.038434 | 30.450261 | 809.97 | 1 | 4 | 1 | 2 | 2014 | 1 | 4 | 1 | 1 | 1 | 1.946018 | -0.780493 | -0.424949 | 2.440005 | 0.0 | -0.312355 | 0.778170 | 4.062019 | 7.322191 | 13.759314 | 6.954507 | 0.0 | 0.589386 | 279.510713 | 1057.97 | 582.193117 | 78.59 | 40.0 | -0.476122 | 312.745952 | mobile | 3 |